Experiment, Experiment, Experiment


Two months ago I went for a walk (as John Green once said, I have to fucking walk for my fucking mental health) and put on the latest ATP episode expecting just some comfortable nerdery on the MacBook Neo.
That episode, though, was not just any ATP episode. It was the one in which Marco revealed his Summer project: Transcripts on Overcast.
Podcast transcripts are a somewhat recent trend, appearing on everything from Apple Podcasts to Spotify to other third-party players like Pocket Casts in the last 2 years or so. Their main form is blocks of text displayed in the Now Playing screen, with words highlighted as they're spoken so users can follow along with their eyes as well as their ears (very similar to lyrics in Apple Music and Spotify).
Apple Podcasts' implementation of transcripts. I love that I caught some UI bugs while recording this example lol.
Another convenience brought by them is easy searching and referencing, but I haven't seen players lean too much into that. Some shows publish them online for separate referencing, but for this blog post whenever I mention transcripts I'm referring to their in-app form.
Recently I added podcast episodes to my Medo e Delírio app. It's a companion app to the Medo e Delírio em Brasília podcast, primarily focused on sharing small sound bites from the show, and being able to listen to the full episodes is a recent addition.
Since shipping basic episode playback, I started working on new episode notifications and coming up with all sorts of new ideas for this little nook. When I heard Marco start narrating his Summer 2025 hobby, things started to make too much sense.
What Marco did
First, for those who don't know, Marco Arment is an indie iOS developer, podcaster, and blogger best known for creating Instapaper, co-founding Tumblr, and hosting the Accidental Tech Podcast.
Marco experimented with Apple's SpeechAnalyzer API. Introduced in iOS 26 and used extensively throughout Apple's built-in iOS apps, it gives you on-device speech to text. According to Marco, it's super fast and has pretty good accuracy. In his tests, he was able to transcribe 200 minutes for every 1 realtime minute with his Mac. From the man himself:
[ATP 683, 58:20] Marco Arment: So I was doing all this development on my laptop over the summer. And I noticed that it was able to transcribe.
If I ran a few jobs in parallel, I could have one M4 Mac transcribe audio at about 200x the audio's playtime.
So in other words, about 200 minutes transcribed for every real-time minute that has passed.
Casey Liss: Goodness.
After some mathing, he figured that the base model Mac Mini was the best bang for the buck for transcribing episodes. Then, after a while, Marco once again made every nerd's biggest dream a reality which is to spend big amounts of money on tech under the excuse of investing in his own business. He bought 48 base model M4 Mac Minis.

Honestly, kudos. I wish I could do that.
He eventually leased a space in a server rack place and installed his army of Macs, learning about power consumption, UPSs and heat dissipation. His app, Overcast, requires this kind of scale, since it's basically an Apple Podcasts replacement, dealing with thousands of podcasts, with new episodes every day.
On these Macs, he runs special Mac software he wrote to coordinate the workload, distributing the computers between languages and shows. I loved hearing about this so much. It tickled the exact right spot in my nerdy brain.
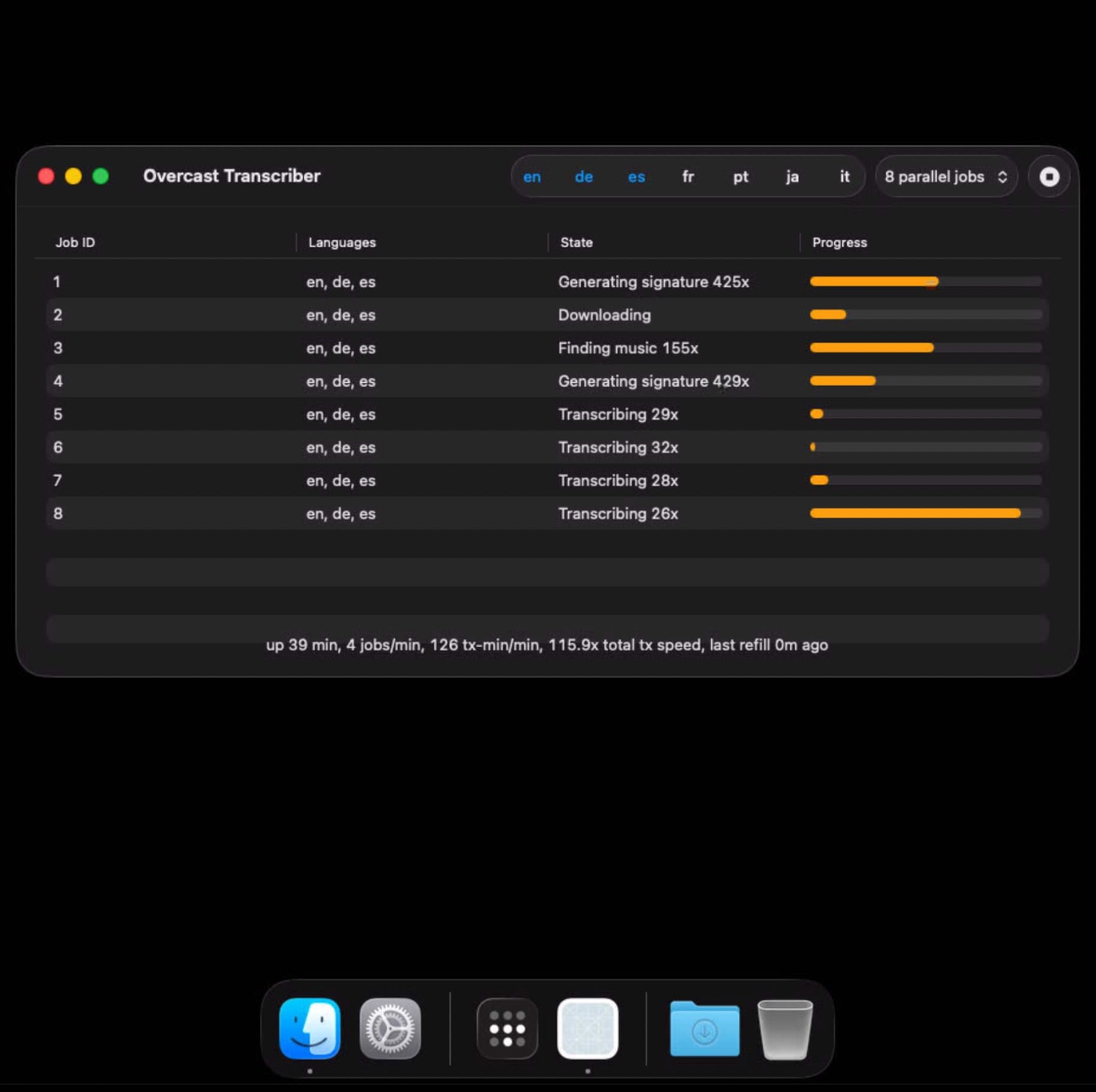
I got home after my walk and was just mesmerized by the power of being a huge nerd about something and following through on ideas.
How I did it
I do tons of chatting with Claude to discuss feature ideas for my apps and see what makes sense, expand some small embryos and the like. I figured Claude was going to berate me for wanting to work on yet another big feature before shipping the ones I had committed to like it did when we were working on my other app, Dùn.
But to my surprise, when I asked if this idea could make sense for M&D it said it could. And then started elaborating on possible paths.
One of the first things it suggested was whisper.cpp, an open source port of OpenAI's speech to text model that first came out in 2022. I had come into contact with whisper through MacWhisper, a paid GUI wrapper on top of the models, whose evolution I followed online.
The thing is I didn't pay too much attention to the free and on-device parts when first learning about whisper. I got excited and set out exploring.
First I downloaded the latest episode's MP3 and ran it through the beefiest model on my work Mac, a 16" M4 Max MBP. The results were awesome! Readable Portuguese, close to no visible mistakes.
I also experimented with first passing the MP3s through ffmpeg to make them mono audio and downsampling the bitrate a little since an AI shouldn't really care if it's processing audio in mono or stereo lol.
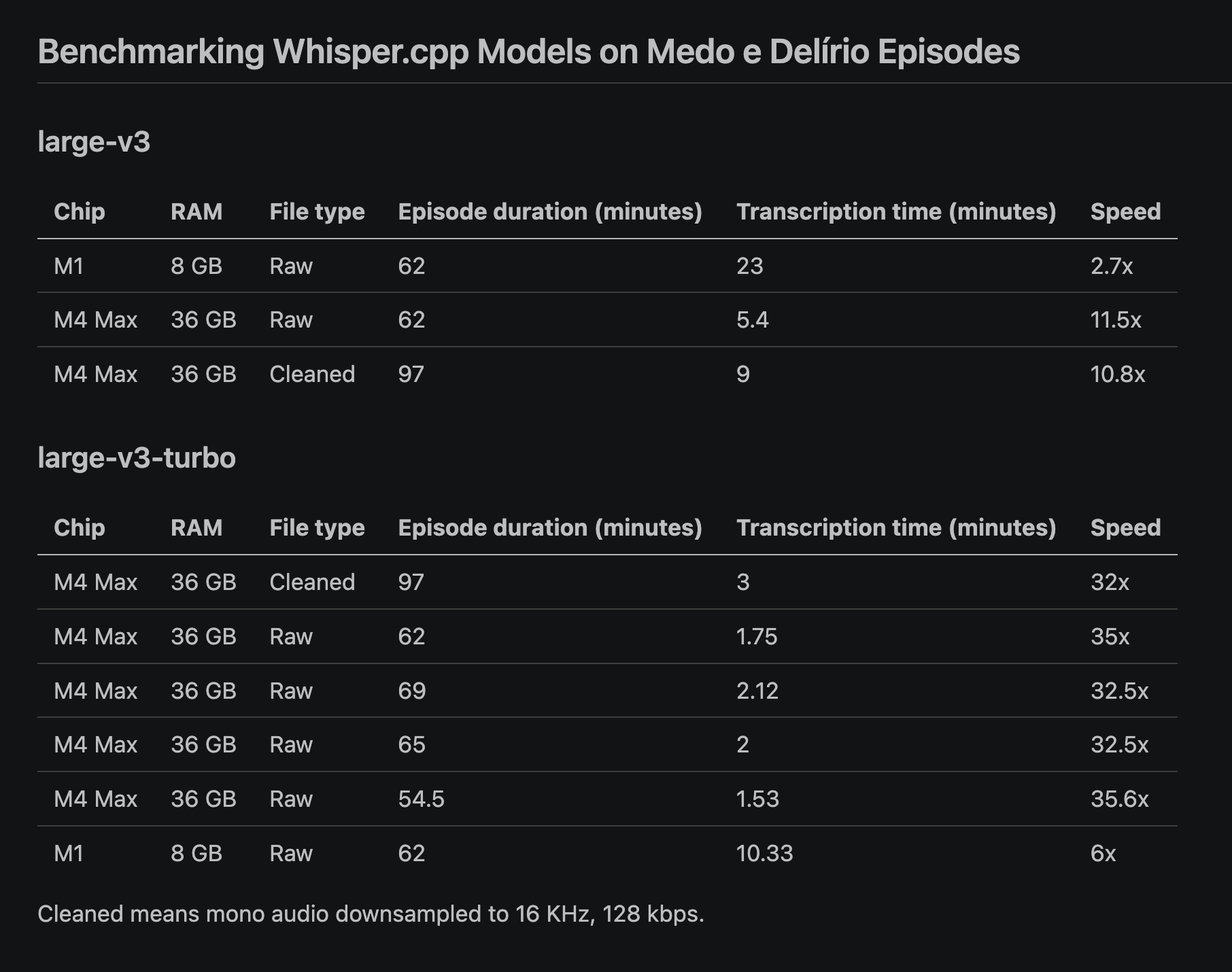
To my surprise, large-v3-turbo, a distilled model OpenAI put out in 2024 with a much smaller decoder, was the sweet spot and my ffmpeg "cleaning" process actually made the model process episodes slower.
I had a blast experimenting with the models and creating this benchmark. My personal M1 MBA almost burst into flames 😂 but it did manage to run a simplified version of the models.
I could not get quite as close to 200x real time as Marco did but here's the reality of my app: instead of thousands of podcasts, Medo e Delírio is a single show, with a single feed and (mostly) in a single language (Portuguese). That reduces my scope significantly.
Spike it, baby
I'm a strong proponent of spiking low-understanding tickets in my day job. I believe that going in with a mindset of "I'm just trying this out, not committing to an outcome" gives you at least half the stamina you need to really dig into something technical and come out with a workable solution. Building these transcripts was a spike in exactly that spirit.
From idea to a finished version I believe it was only 3 days. I did use AI extensively to work through problems and code. Unfortunately I am not going to buy hundreds of Mac Minis like Marco did. Instead, I worked with Claude to build a script that checks the podcast feed every 20 minutes and, if it finds a new episode, runs whisper.cpp and uploads the new transcript file to the server on the spot. I set it to run on this M4 Max MBP outside of work hours, and that has been enough ever since I put out version 11.5 of Medo e Delírio with transcripts in early April 2026.
One of the decisions I made was to version the transcripts endpoint in case I decide to work on an improved version in the future. This allows old versions of the app to still get what they need while newer versions hit a v2 or v3 endpoint. To manage syncing and diffing, a manifest lives in the root of the v1 endpoint. It contains episodeId and a hash of the file in case I update a bad transcript:
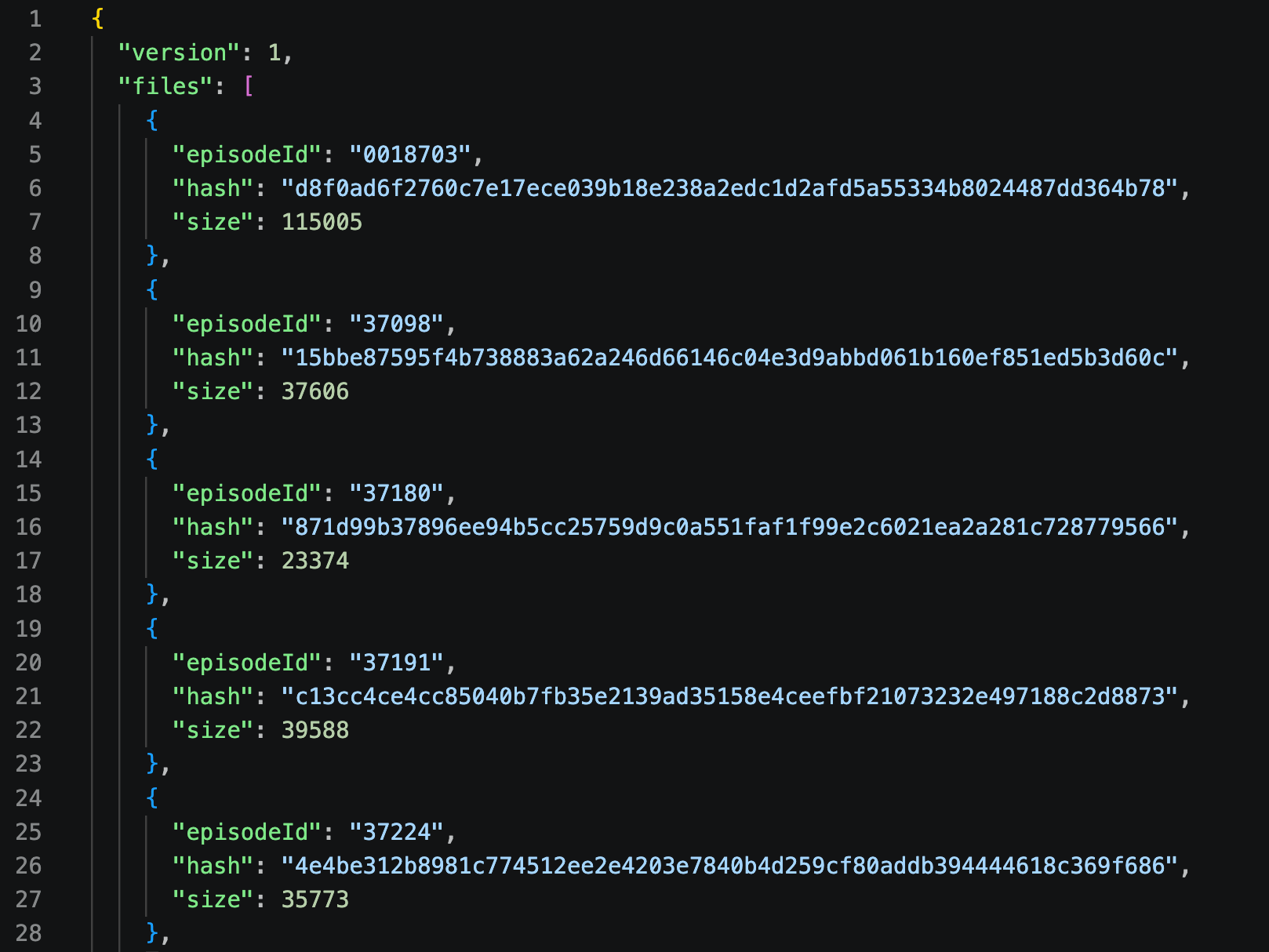
All the app has to do is download this small JSON and check if it's missing a .srt.
Speaking of SRTs, you might be familiar with this if you ever (hem hem) had to watch video files that required subtitles. The kind that falls off the back of trucks. Turns out that's the perfect format for syncing audio and text here too:
Sample of transcripts inside the app (with audio).
A parser splits content on double newlines, parses each block's HH:MM:SS,mmm --> HH:MM:SS,mmm timestamp line, and produces an array of SRTCue structs (index, startTime, endTime, text). TranscriptProvider tracks the current playback time and uses a binary search over the cues array to find which cue is active. It exposes previous/current/next cues so the UI can show context.
I'm very happy with this current version and am already working on more.
My main takeaway for those reading thus far is: just try shit out. Just go try it. If it sounds fun in your mind, go do it. You can't know the results for sure if you just keep overthinking it.